

詢問任何經驗豐富的 DBA 哪一項改動最能顯著提升查詢效能,答案幾乎如出一轍:建立對的索引。然而,索引也是資料庫開發者工具箱中最常被誤解的雙面刃。許多開發者往往在效能出問題後才盲目新增索引、在不確定時又猶豫是否移除,甚至只因為不確定有哪些替代方案而選錯了索引類型。本指南將帶你認識幾種核心的索引類型——B-tree、雜湊(Hash)、部分(Partial)與複合(Composite)索引——解釋各自的最佳適用場景,並展示 Navicat 的資料表設計器如何化繁為簡,讓索引的建立與管理變得直覺又高效。
為何索引至關重要
索引是一種獨立的資料結構,由資料庫在資料表旁同步維護,旨在無需掃描每一列資料就能精準解析特定的查找需求。若未在頻繁查詢的欄位上建立索引,資料庫每次都必須執行全資料表掃描。這種做法在幾千列資料時或許影響微乎其微,但在面對數百萬列資料時,查詢就會變得無比緩慢。然而,這背後存在著權衡:每個索引都會增加寫入作業的負擔,因為每次執行插入、更新或刪除作業時,資料庫在更新資料表的同時,也必須同步更新索引。因此,審慎配置而非盲目增設索引,正是區分「讀取快卻寫入低效的架構」與「調校良好的高質量架構」的分水嶺。
B-Tree 索引:明智的預設設置
B-tree(平衡樹)索引是絕大多數資料庫引擎的預設選擇,這背後有著極其扎實的架構原因。它將數值儲存在排序好的分層結構中,這使得它不論在處理精確比對、範圍查詢還是排序作業時都展現出極高的效率。如果你的查詢包含 WHERE 子句,且使用 =, <, >, BETWEEN, 或 LIKE ‘prefix%’ 來比較欄位,那麼建立 B-tree 索引幾乎是毫無疑問的首選。
初學者常忽略的一點是,B-tree 索引本身就具備的排序特性。如果你的查詢使用索引欄位對結果進行排序,資料庫就能直接依序讀取索引,而無需對整個結果集進行排序,這能在大型資料表上帶來實質性的效能提升。
雜湊索引:快速但局限
雜湊(Hash)索引儲存的是將每個欄位值計算後得到的雜湊值,而非數值本身。這使得它們在進行精確比對查找時速度極快;資料庫只需計算搜尋條件的雜湊值,便能直接跳轉到相符的條目。然而它的限制也很明顯,雜湊索引對於範圍查詢或排序幾乎沒有用處。原因是雜湊後的數值並不具備有意義的順序。此外,它們也不支援多欄位查找。
雜湊索引最適合應用於僅透過等值比對(=)查詢、且數值重複率極低的欄位,例如 UUID 或階段作業記號。在 MySQL 中,雜湊索引僅限於 MEMORY 資料表使用;而在 PostgreSQL 中,它們則是常規資料表完整支援的選項,並在近期的版本中變得越來越成熟穩健。
部分索引:僅針對查詢內容建立索引
部分(Partial)索引(在 SQL Server 中也被稱為篩選索引)僅針對資料表中滿足特定條件的子集進行建立。舉例來說,若你的訂單資料表擁有數百萬列資料,但應用程式幾乎只會查詢狀態為 ‘pending’ 的訂單,此時在 status 欄位加上 where status = ‘pending’ 的部分索引,其檔案體積將遠小於完整索引,且搜尋速度也會大幅提升。
部分索引對於軟刪除模式具備極高的價值,在這種模式下,高比例的資料列會被標記為已刪除且極少被查詢。將這些資料列排除在索引之外,可以保持索引的精簡,並能讓你的查詢規劃器運作得更順暢。PostgreSQL 對部分索引提供了完善的原生支援,而 SQL Server 也能透過語意幾乎相同的篩選索引來達到相同的效果。
複合索引:欄位順序決定一切
複合(Composite)索引跨越了多個欄位,當設計得當時,它甚至可以完全不觸及底層資料表就滿足複雜的多欄位查詢。然而,需要理解的關鍵原則是,複合索引只能從左至右依序使用。一個建立在 (last_name, first_name) 上的索引,能夠協助針對 last_name 進行篩選的查詢,或是同時針對 last_name 與 first_name 進行篩選的查詢,但若查詢僅針對 first_name 進行篩選,該索引將完全無法發揮任何效用。
在排列複合索引的欄位順序時,通用規則是將最具選擇性的欄位放在最前面,即能篩選掉最多資料列的欄位。此外,用於等值條件(=)的欄位應該放在用於範圍條件(>, <, BETWEEN)的欄位之前。這是因為一旦在索引的特定節點上觸發了範圍條件,將會導致最佳化器無法繼續利用該索引的其餘欄位。
使用 Navicat 的資料表設計器管理索引
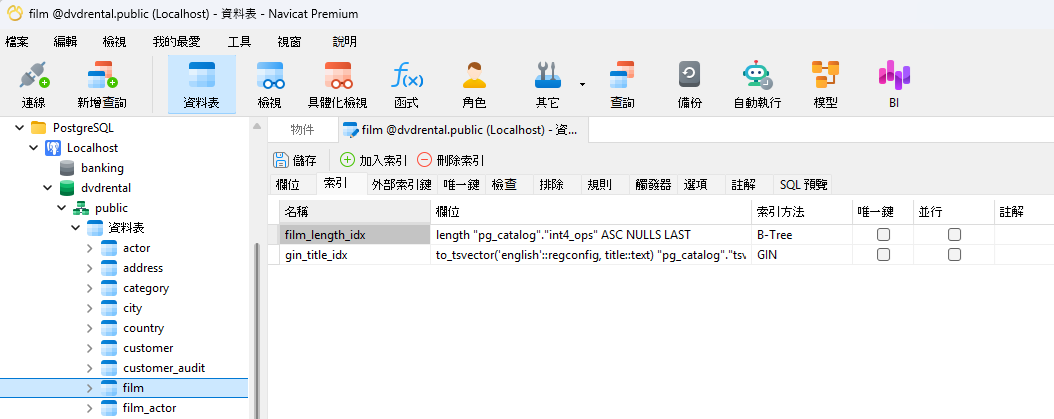
Navicat 的資料表設計器 提供了一個實用且視覺化的環境,讓你無需手動撰寫 DDL 即可建立與管理上述所有索引類型。索引是在設計器中專屬的「索引」頁籤內進行處理,與定義欄位的「欄位」頁籤相互獨立,這種分離設計讓使用者能一目了然地審視資料表的索引策略。
若要新增索引,你只需為其命名、勾選要涵蓋的一個或多個欄位,並從下拉式選單中挑選對應的索引類型與方法。至關重要的是,這些下拉式選單中的選項會完全根據你所連線的特定資料庫量身打造。如果你在 MySQL 中作業,你選單只會呈現 MySQL 支援的規格;一旦切換到 PostgreSQL 連線,選項便會反映出 PostgreSQL 的功能,包括 B-tree、hash、GIN、GiST 等。這種情境感知意味著你無需盲目猜測目標資料庫到底支援哪些索引。
對於複合索引,你可以在單一索引條目中加入多個欄位,並重新排序以符合你預期的欄位優先級——正如前面所提到的,這個欄位排序將直接決定該索引是否能成功觸發、以及如何被所利用。此外,主索引鍵欄位會在「欄位」頁籤中清晰標記並可見,而所有次級索引則會集中在「索引」頁籤中。
總結
優秀的索引策略,核心從不在於數量多,而在於精準配置。B-tree 索引涵蓋了絕大多數日常查詢模式;雜湊索引在局限的精確比對場景中佔有一席之地;部分索引讓你在你只查詢資料子集時能維持系統的精簡;而複合索引只要欄位順序正確,則能發揮超越多個單欄位索引的加乘效益。徹底理解這些結構差異,並善用像 Navicat 的資料表設計器這樣的工具來高效實作與驗證,你將能處於強大優勢,確保系統在資料量暴增的未來依然能穩健地高速運行。







