

Joins and subqueries are both used to combine data from different tables into a single result set. As such, they share many similarities as well as differences. One key difference is performance. If execution speed is paramount in your business, then you should favor one over the other. Which one? Read on to find out!
The Verdict
I won't leave you in suspense, between Joins and Subqueries, joins tend to execute faster. In fact, query retrieval time using joins will almost always outperform one that employs a subquery. The reason is that joins mitigate the processing burden on the database by replacing multiple queries with one join query. This in turn makes better use of the database's ability to search through, filter, and sort records. Having said that, as you add more joins to a query, the database server has to do more work, which translates to slower data retrieval times.
While joins are a necessary part of data retrieval from a normalized database, it is important that joins be written correctly, as improper joins can result in serious performance degradation and inaccurate query results. There are also some cases where a subquery can replace complex joins and unions with only minimal performance degradation, if any.
Examples of Subqueries
Sometimes you can't easily get at the data you want using a subquery. Here are a couple of examples using the Sakila Sample Database for MySQL and the Navicat Premium database development and admin client.
Example #1: Using an Aggregate Function as Part of a Join Clause
Most of the time, tables are joined on a common field. In fact, the common fields often share the same name in order to show that they refer to the same piece of information. But that is not always the case. In the following query, the customer table is joined to the latest (MAX) create_date so that query results pertain to the customer with the most recent sign up date:
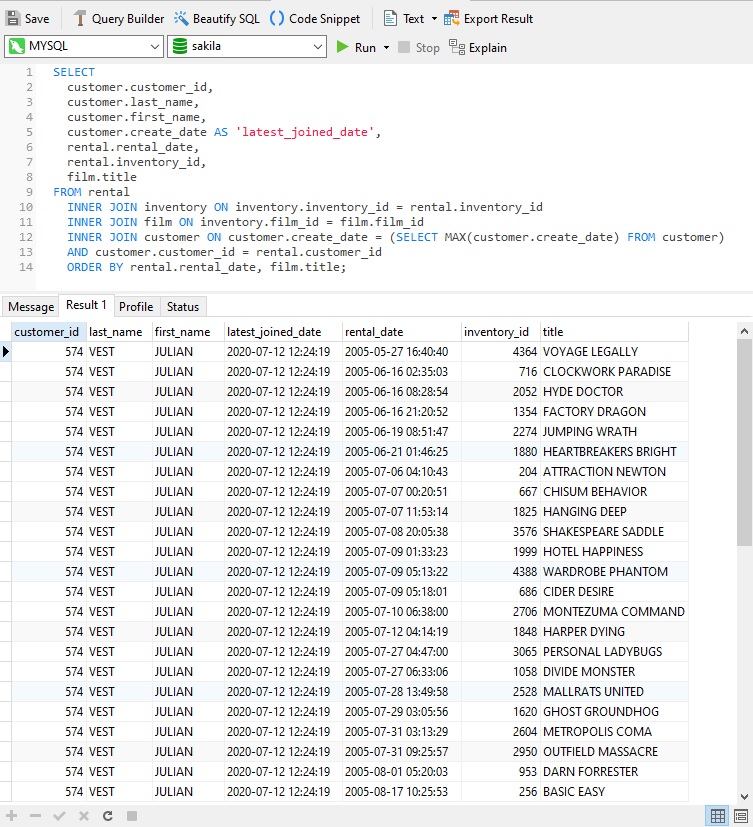
In the above SELECT statement, a subquery is employed because you cannot use aggregate functions as part of a WHERE clause. This ingenious workaround circumnavigates that limitation!
Example #2: Double Aggregation
In this example, a subquery is employed to fetch an intermediary result set so that we can apply the AVG() function to the COUNT of movies rented. This is what I call a double aggregation because we are applying an aggregation (AVG) to the result of another (COUNT).
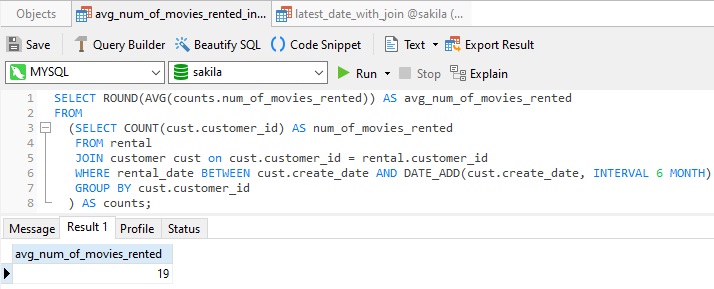
This particular query is quite fast - taking only 0.044 seconds - because the inner query returns a single (scalar) value. Usually, the slowest queries are those that require full table scans, which is not the case here.
Conclusion
While both joins and subqueries have their place in SQL statements, I would personally recommend that you always try to write your queries using joins exclusively. Only when you cannot fetch the data you're interested in without a subquery, should you introduce one.
Interested in Navicat Premium? You can try it for 14 days completely free of charge for evaluation purposes!







