

Column Names
Welcome to the 2nd installment on SQL naming conventions. As mentioned in part 1, naming conventions are a set of rules (written or unwritten) that should be utilized in order to increase the readability of the data model. These may be applied to just about anything inside the database, including tables, columns, primary and foreign keys, stored procedures, functions, views, etc. Having covered the rules for naming tables in part 1, we'll be looking at column names in this installment. Other database objects such as Procedures, Functions, and Views will be explored in part 3.
The Primary Key Column
The primary key is a field or a combination of fields in a table that uniquely identify the records in the table. A table can have only one primary key. As such, many DBAs prefer to simply name this column "id". Other's append the "_id" suffix to the table name, as seen here in the Sakila Sample Database:
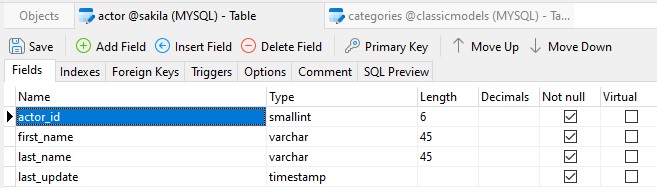
Likewise, you should also assign your PK constraint a meaningful name. The naming convention for a primary key constraint is that it should have a "pk_" prefix, followed by the table name, i.e. "pk_<table_name>".
Foreign Key Columns
A foreign key is a field in the table that references a primary key in other tables. A good rule to follow is to use the referenced table name and "_id", e.g. customer_id, employee_id. This will help us identify the field as a foreign key column and also point us to the referenced table.
Here's a city table that contains a foreign key to the country table's country_id field:
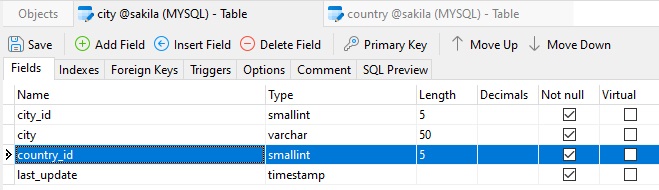
The naming convention for a foreign key constraint is to have an "fk_" prefix, followed by the target table name, followed by the source table name. Hence, the syntax should be "fk_<target_table>_<source_table>".
Following the foreign key constraint naming convention for the city table would give us the name "fk_city_country":

Data Columns
In the section on Describing Real-World Entities in Part 1, it states:
Any time that you're naming entities that represent real-world things, you should use their proper nouns. These would apply to tables like employee, customer, city, country, etc. Usually, a single word should exactly describes what is in that table.
The same rules can and should be applied to data columns. Again, you should use the least possible words to describe what is stored in that column, e.g., country_name, country_code, customer_name. If two tables will have columns with the same name, you could add something to keep the name unique, although that's not strictly necessary as table prefixing will differentiate the columns in queries. Nonetheless, having unique names for each column is helpful because it reduces the chance to later mix these two columns while writing queries. Names like customer_name city_name are likely to come up in more than one table. If that concerns you, you can always make the names more descriptive, such as order_customer_name or city_of_residence_name.
Dates
For dates, it's good practice to describe what the date represents. Names like start_date and end_date are pretty common and generic. You can describe them more precisely by using names like call_start_date and call_end_date.
Final Thoughts on Naming Conventions for Column Names
You probably noticed from all of the examples presented that both table and column names should be in lowercase with words separated by an underscore ("_"). For example, customer_name and invoice_date as opposed to customerName and invoiceDate. This works well with the SQL style convention of capitalizing statements names, clauses, and other keywords for better code readability, e.g. SELECT customer_name, invoice_date FROM orders;







