

Many database administrators (DBAs) spend at least some of their time trying to identify and remove duplicate records from database tables. Much of this time could be diverted to other pursuits if more attention was paid to preventing duplicates from being inserted in the first place. In principle, this is not difficult to do. However, in practice, it is all-too-possible to have duplicate rows and not even know it! Today's blog will present a few strategies for minimizing the occurrence of duplicate records in your database tables by preventing them from being inserted into a table.
Employ PRIMARY KEY and UNIQUE Indexes
To ensure that rows in a table are unique, one or more columns must be constrained to reject non-unique values. By satisfying this requirement, any row in the table may be quickly retrieved via its unique identifier. We can enforce column uniqueness by including a PRIMARY KEY or UNIQUE index on the applicable fields.
To illustrate, let's take a look at a table that contains product details such as the name, line, vendor, description, etc. Here it is in the Navicat Table Designer:
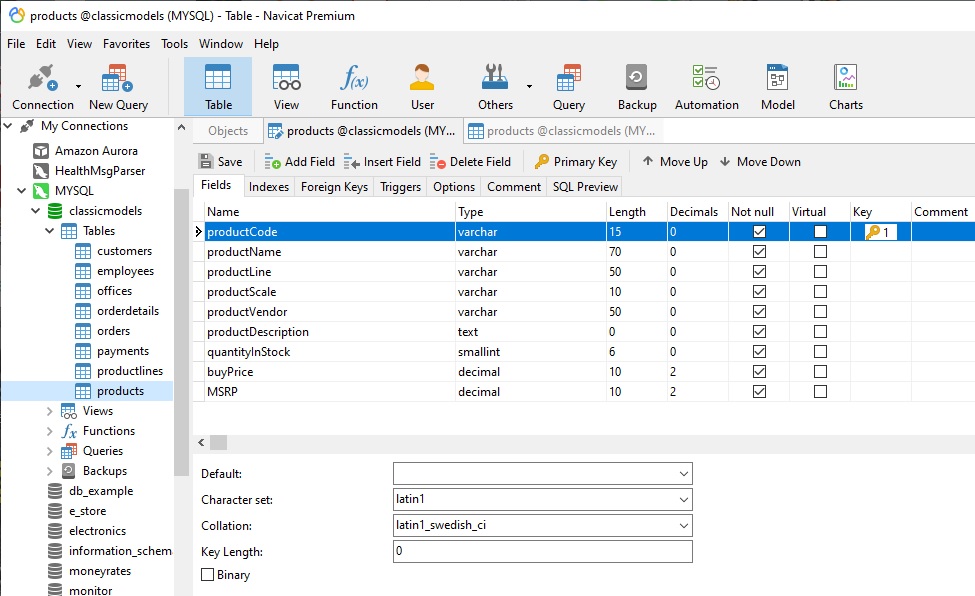
Navicat indicates fields that are part of a KEY using a key icon under the Key heading, along with a number that denotes its position within a composite key. A single key with a number 1 tells us that the productCode is the sole Primary Key (PK) column for the table. By definition, the PK must be unique and may not contain NULL values.
Meanwhile, if we then take a look at the Indexes tab, it shows that the productLine column is indexed as well:

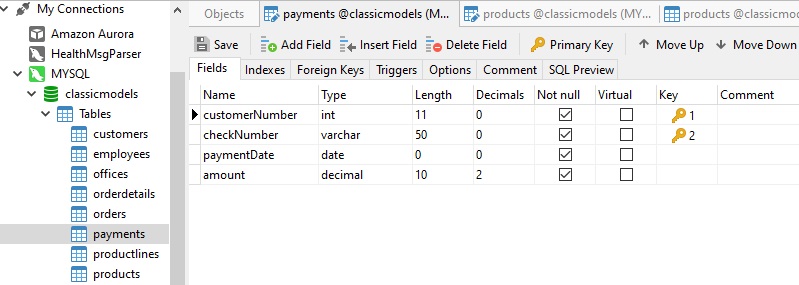
In many instances, a single column is not sufficient to make a row unique, so we must add additional fields to the PK. Here's a payments table that requires both the customerNumber and checkNumber to make a unique PK because the same customer can make several payments:
The Downside of Auto-incrementing Primary Keys
Many database designers/developers (myself included!) love using numeric auto-incrementing PKs because:
- Ease of use. The database takes care of them for you!
- Collisions are impossible because each new row receives a unique integer.
Here is just such a table:
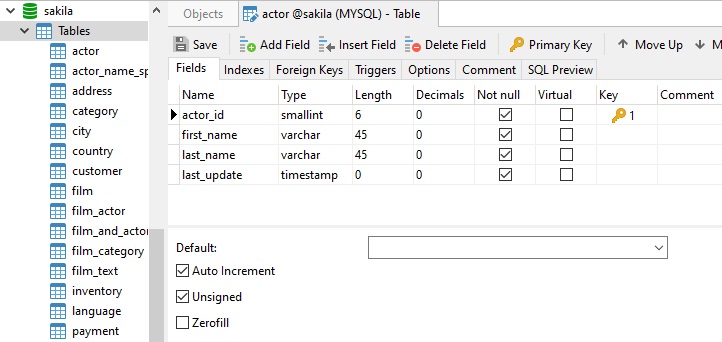
In Navicat, all you need to do to create an auto-incrementing PK is to choose a numeric data type (such as an integer) and check the Auto Increment box. That will cause all values for that column to be generated by the database.
And now for the bad news; auto-incrementing PKs do little to prevent duplicate rows - especially if you don't include any other table indexes. For example, imagine that the above table did not have any additional indexes. There would be nothing stopping someone from inserting a row with the exact same first_name and last_name as an existing row.
In fact, we can put that theory to the test right now! In Navicat, we can insert a new row directly into the Grid by clicking the plus (+) button:
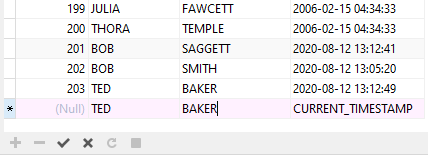
As expected (feared), the duplicate name was accepted!

Conclusion
The moral of today's story is that, while one can prevent duplicate rows from being inserted, this does not necessarily mean that all data duplication can be prevented. At a minimum, designers/developers must take additional precautions by either employing rigorous normalization in database design or by performing specific validation at the application level.







