

將 DISTINCT 關鍵字加入 SELECT 查詢後,查詢僅傳回指定欄清單的唯一值,以便從結果集中移除重複的列。由於 DISTINCT 會在 SELECT 的欄清單中的所有欄位運作,因此不能將其用於一組欄位中的其中一個欄位。話雖如此,但是也有多種方法可以無視其他欄並從一欄中移除重複的值。今天,我們將在這裡介紹其中幾種。
測試資料
為了測試我們的查詢,我們需要一個包含重複資料的資料表。為此,我在 Sakila 範例資料庫的 customer 資料表中加入了一些額外的電子郵件地址。這是 Navicat Premium 的網格檢視的螢幕擷取畫面,顯示有一個客戶擁有 2 個關聯的電子郵件地址:
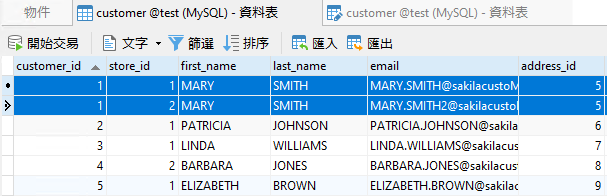
如果現在將 DISTINCT 子句加入欄位清單包含其他欄的查詢中,這是行不通的,因為整列是唯一的:
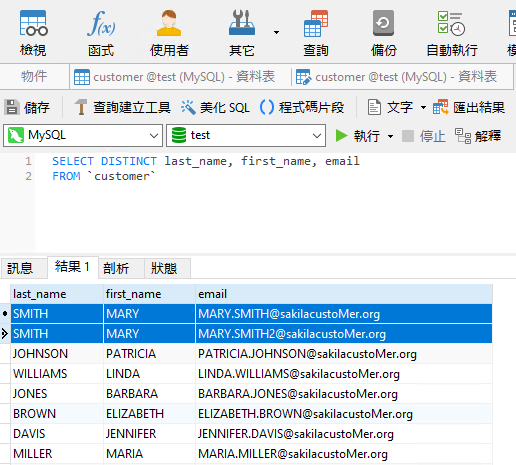
那麼,什麼才真的有效?讓我們找出答案!
使用 GROUP BY
GROUP BY 子句根據一個或多個欄位分組結果,將彙總函式用於特定的資料子集。當與 MIN 或 MAX 之類的函式結合使用時,GROUP BY 可以將一個欄位限制為相對於另一個欄位的第一個或最後一個執行個體。
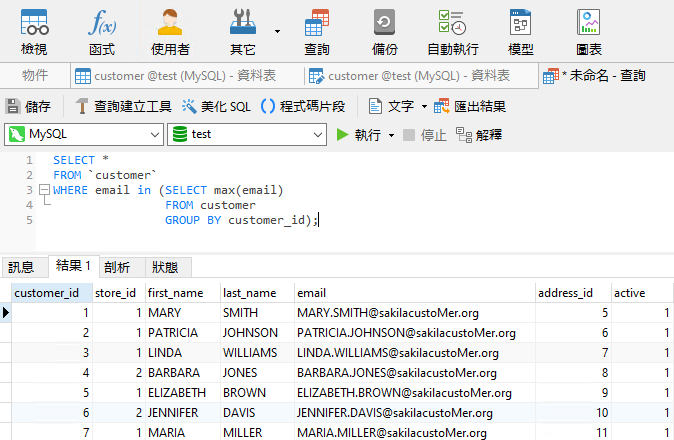
因此,如果我們希望將每個客戶的電郵地址限制為一個,則可以包含一個子查詢,該查詢根據 customer_id 分組電郵地址。然後,我們可以將 email 欄與子查詢傳回的唯一欄相結合來選取其他欄:
使用視窗函式
另一個方法(略為進階的方案)是使用視窗函式。被命名為視窗函式是因為它們對一組與目前列相關的資料表列進行計算。與一般彙總函式不同,視窗函式不會導致列被分組為單一輸出列,從而使列保留其各自的特性。
ROW_NUMBER() 是一個視窗函式,為結果集分割中的每一列指派一個連續的整數,每個分割的第一列從 1 開始。對於客戶的電郵地址,第一個電郵地址傳回 1,第二個電郵地址傳回 2,以此類推。然後我們可以使用該值(以下稱為「rn」)只選取每個客戶的第一個電郵地址。
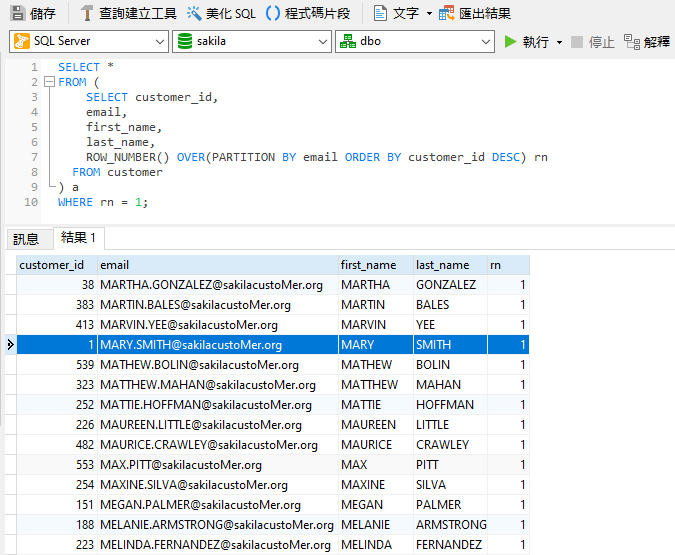
值得注意的是,並不是所有的關聯式資料庫都支援視窗函式。SQL Server 支援,而 MySQL 在版本 8 中加入視窗函式。
總結
在今天的文章中,我們學習了如何使用 GROUP BY 和視窗函式從一組欄位中的其中一個欄位中刪除重複項目。毫無疑問,還有很多其他方法可以實現相同的最終目標,但是這兩種可靠的技術應該更切合你的需要。
如果你對 Navicat Premium 感興趣,可以免費試用 14 天!




