在 Navicat for MySQL、PostgreSQL、SQLite、MariaDB 和 Navicat Premium 的非 Essentials 版本中,查詢建立工具是一個以視覺化方式建立和編輯查詢的工具。第 4 部分描述了如何在查詢中使用原生 SQL 彙總函式以顯示欄的統計資料。本部分將介紹如何使用查詢建立工具根據 HAVING 條件篩選已分組的資料。
關於 Sakila 範例資料庫
我們今天將在此處構建的查詢將在Sakila 範例資料庫執行。它包含許多以電影業為主題的資料表,涵蓋了演員和電影製片廠以至影碟出租店的所有內容。如需下載和安裝 Sakila 資料庫的說明,請參閱Generating Reports on MySQL Data(產生 MySQL 資料的報表)教學。
使用 HAVING 子句篩選結果群組
SQL HAVING 子句是與 GROUP BY 子句結合使用,以根據一個或多個準則限制傳回列的群組。與在 GROUP BY 子句之前用的 WHERE 子句相比,HAVING 子句在 GROUP BY 子句將列進行彙總之後再篩選它。
判斷有多少名演員有相同姓氏
如果我們想知道資料庫中有多少名演員與至少兩名其他演員有相同的姓氏,我們可以使用 GROUP BY 子句根據 actors 資料表的 last_name 欄位將演員進行彙總。
我發現無論是使用查詢編輯器還是查詢建立工具構建查詢,都是最好先選擇資料表。
- 考慮到這一點,開啟查詢建立工具,按一下 FROM 關鍵字旁邊的 <按這裡加入資料表> 標籤,然後從清單中選擇 sakila.actor 資料表:
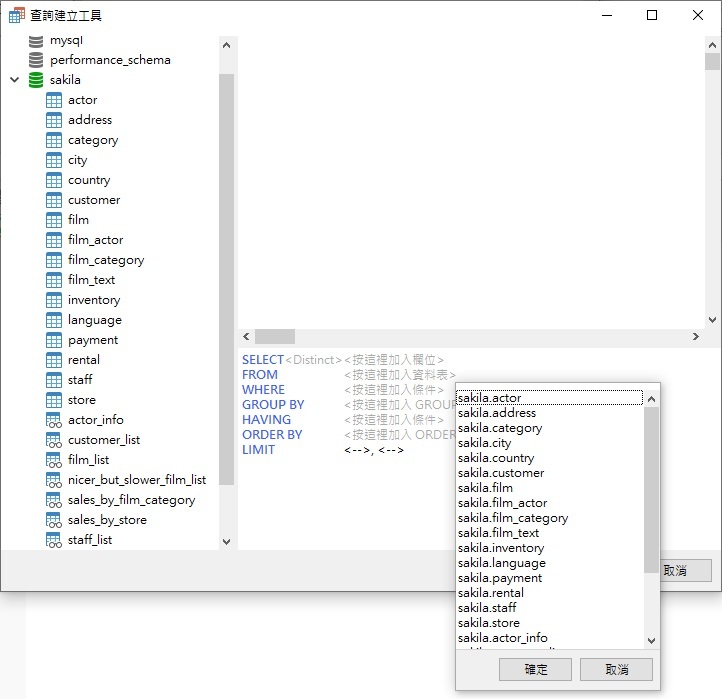
- 頂部窗格會出現 actor 資料表和它的所有欄位。我們需要兩個欄位:last_name 和列數。按一下資料表中 last_name 欄位旁邊的方塊:
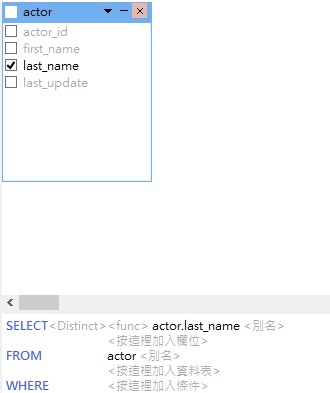
若要將 Count 函式加到欄位清單,請按一下 SQL 語句中 actor.last_name 欄位下面的 <按這裡加入欄位>標籤,然後在彈出式對話方塊的「編輯」索引標籤中輸入「Count(*)」:
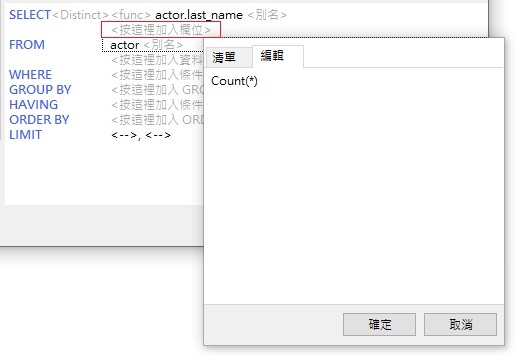
- 下一步是加入 GROUP BY 子句。請按一下 <按這裡加入 GROUP BY>標籤,然後從彈出式對話方塊中選擇 actor.last_name 欄位。
- 按一下「確定」按鈕以關閉「查詢建立工具」。
這將把以下的 SQL 加至查詢編輯器中:
SELECT actor.last_name, Count(*) AS last_name_count FROM actor GROUP BY actor.last_name
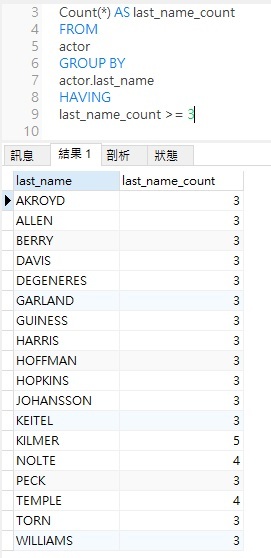
以下是上述查詢的結果:
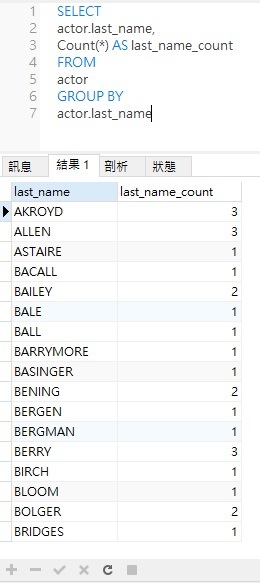
如你所見,結果是以 last_name 分組和排序。但它沒有將結果限制演員為與至少兩個其他演員有相同的姓氏。因此,我們需要加入 HAVING 子句。
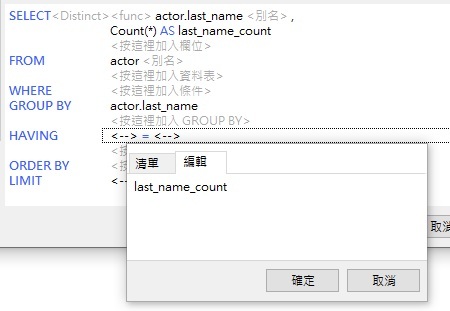
- 重新開啟查詢建立工具,然後按一下 HAVING 關鍵字旁邊的 <按這裡加入條件> 標籤。這將插入一個「<--> = <-->」運算式標籤。
- 按一下運算式左邊的「<-->」標籤。因為欄位清單只含有資料表欄位,所以 last_name_count 欄位不會出現在清單中。因此,請在「編輯」索引標籤中輸入 last_name_count:
- 接下來,按一下等於「=」標籤以開啟比較運算子清單。從清單中選擇「大於或等於」(>=)運算子:
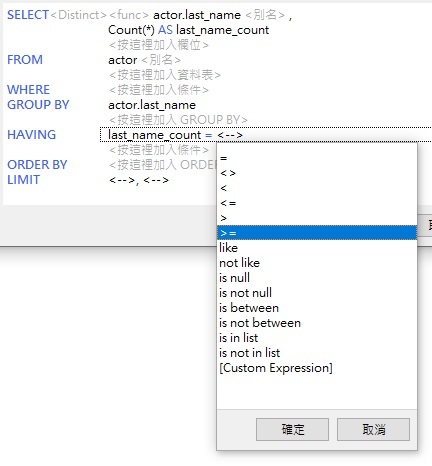
- 最後,按一下運算式右邊的「<-->」標籤,然後在「編輯」索引標籤中輸入「3」。
- 按一下「確定」按鈕以關閉「查詢建立工具」。
這將在查詢中加入「HAVING last_name_count >= 3」運算式。這次查詢只顯示在資料表中姓氏出現超過兩次的演員: