

Durante años, muchas empresas han dependido de simples comprobaciones de tiempo de actividad para evaluar el estado de sus bases de datos. Es fundamental saber que su base de datos está funcionando correctamente, el tiempo de actividad por sí solo no dice prácticamente nada sobre el rendimiento, la eficiencia ni la experiencia del usuario. Una base de datos puede estar técnicamente "activa" mientras entrega consultas extremadamente lentas, sufre contención de recursos o está al borde del agotamiento de su capacidad. La monitorización moderna de bases de datos requiere de un enfoque más sofisticado, el cual se centre en las métricas que realmente impactan en sus aplicaciones y usuarios.
Métricas de rendimiento de Consultas
El área más crítica que se debe monitorizar es el rendimiento de las consultas, ya que estas son donde su base de datos interactúa directamente con sus aplicaciones. Las consultas de larga duración suelen ser la señal de alerta de problemas más graves. Al rastrear los tiempos de ejecución de las consultas, puede identificar qué consultas específicas consumen recursos excesivos y causan embudos. Igual de importante es comprender los tiempos de espera de las consultas, que revelan qué esperan sus consultas, ya sea acceso al disco, bloqueos o recursos de red.
Más allá del tiempo de ejecución, examinar las consultas principales según el uso de CPU ayuda a identificar qué operaciones son más costosas computacionalmente hablando. De igual manera, rastrear las consultas según el número de lecturas y escrituras que realizan puede revelar patrones ineficientes de acceso a datos que podrían beneficiarse de la optimización de índices o la refactorización de consultas. Estas métricas transforman las preocupaciones abstractas sobre el rendimiento en información concreta y práctica.
Utilización y capacidad de recursos
Si bien el uso de CPU y memoria pueden parecer métricas básicas, comprenderlas en contexto es crucial. Los patrones de utilización de CPU indican si el servidor de bases de datos tiene la potencia de procesamiento adecuada para la carga de trabajo; sin embargo, aún más importante, un uso elevado y sostenido de CPU puede indicar índices faltantes o consultas mal optimizadas, en lugar de simplemente hardware insuficiente.
Las métricas de memoria también merecen especial atención, ya que las bases de datos dependen en gran medida del almacenamiento en caché para lograr un buen rendimiento. La tasa de aciertos de la caché del búfer, que mide el porcentaje de solicitudes de datos atendidas desde la memoria en lugar del disco, normalmente debería superar el 90 %. Cuando esta tasa disminuye, indica que la base de datos utiliza frecuentemente el disco para obtener datos, lo que reduce drásticamente el rendimiento. Monitorear la asignación de memoria a lo largo del tiempo también ayuda con la planificación de la capacidad, mostrando si el registro de memoria de su base de datos crece a un ritmo sostenible.
Las métricas de E/S de disco (Disk I/O terminología en inglés) completan el panorama de los recursos. El seguimiento de las operaciones de lectura y escritura de disco por segundo, junto con los tiempos promedios de respuesta del disco, ayuda a comprender si el almacenamiento se está convirtiendo en un embudo o no. La E/S de red es igualmente importante para comprender la cantidad de datos que fluyen entre su base de datos y las aplicaciones.
Conexión y Actividad de sesión
Monitorear las conexiones activas y los detalles de las sesiones proporciona visibilidad sobre cómo sus aplicaciones utilizan realmente la base de datos. El seguimiento de las conexiones actuales de los usuarios le ayudará a comprender su carga de trabajo simultánea y puede alertarle sobre el agotamiento del grupo de conexiones antes de que provoque fallos en las aplicaciones. Monitorear los patrones de conexión a lo largo del tiempo también revela tendencias de uso que fundamentan las decisiones de planificación de la capacidad.
Monitorear bloqueos es especialmente crucial para comprender los problemas de contención. Cuando las consultas esperan bloqueos mantenidos por otras sesiones, los usuarios experimentan retrasos que las métricas simples de CPU o memoria no pueden explicar. Al rastrear tanto los bloqueos actuales como las sesiones en espera de bloqueos, puede identificar patrones de transacciones problemáticos o transacciones de larga duración que bloquean otras tareas.
Medición de estas métricas con Navicat Monitor
Navicat Monitor ofrece una arquitectura sin agentes para la monitorización de bases de datos MySQL, MariaDB, PostgreSQL y SQL Server, lo que significa que no necesita instalar software en sus servidores de bases de datos. La herramienta recopila métricas a intervalos regulares y las almacena en un repositorio para su análisis histórico y análisis de tendencias.
Para la monitorización del rendimiento de las consultas, el gráfico de consultas de larga duración de Navicat Monitor visualiza las consultas más importantes según la duración de la ejecución, los tipos de espera, el uso de la CPU y las operaciones de lectura/escritura. Esto le permite identificar rápidamente aquellas consultas problemáticas y analizar en detalle sus características de ejecución. La herramienta mantiene datos históricos para que pueda controlar si el rendimiento de las consultas se está degradando con el tiempo.
Para la monitorización del rendimiento de las consultas, el gráfico de consultas de larga duración de Navicat Monitor visualiza las consultas más importantes según la duración de la ejecución, los tipos de espera, el uso de la CPU y las operaciones de lectura/escritura. Esto le permite identificar rápidamente aquellas consultas problemáticas y analizar en detalle sus características de ejecución. La herramienta mantiene datos históricos para que pueda controlar si el rendimiento de las consultas se está degradando con el tiempo.
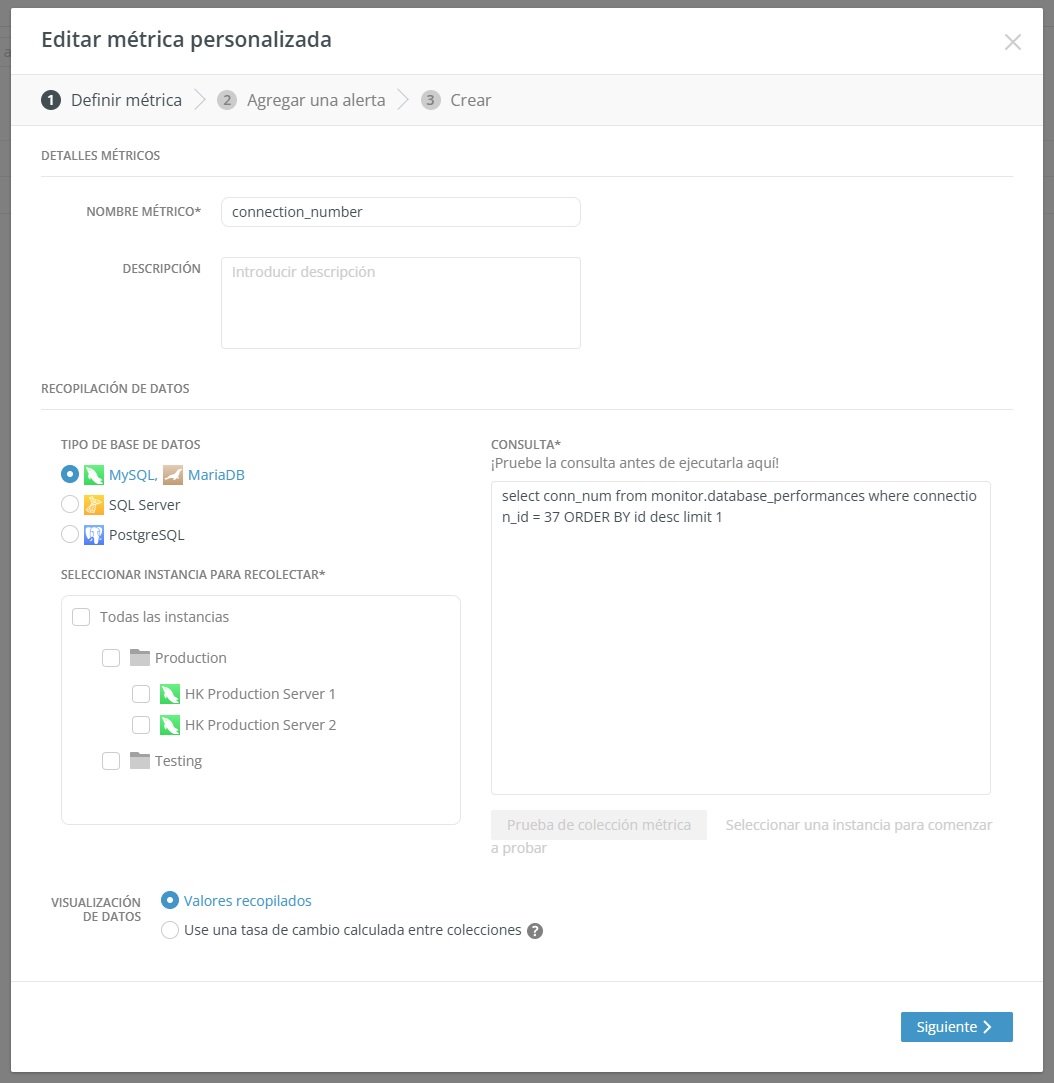
Una función especialmente potente es la capacidad de personalizar métricas. Puede crear sus propias consultas para recopilar métricas de rendimiento para instancias específicas y recibir alertas cuando los valores superen los umbrales definidos. Esto significa que puede supervisar indicadores específicos de su negocio o características de rendimiento especializadas relevantes para sus aplicaciones, yendo mucho más allá de las métricas predefinidas estándar.
El sistema de alertas de Navicat Monitor permite una gestión proactiva al notificarle cuando las métricas superan los umbrales configurables. Puede configurar alertas para cualquier métrica, incluidas las personalizadas, y definir tanto el valor del umbral como el tiempo que debe transcurrir antes de que se active una alerta. Las notificaciones se pueden enviar por correo electrónico, SMS, SNMP o Slack, lo que garantiza que su equipo esté al tanto de los problemas antes de que afecten a los usuarios. La herramienta proporciona un análisis detallado de alertas que incluye gráficos de métricas, cronogramas y contexto histórico para facilitar el análisis de la causa raíz.
Más allá del panel: Métricas procesables
Recopilar métricas es solo el primer paso. El verdadero valor reside en comprender patrones, establecer puntos de referencia adecuados y crear alertas procesables. En lugar de simplemente observar los paneles, establezca rangos normales para sus métricas clave basándose en datos históricos y patrones de carga de trabajo. Esto le permite establecer umbrales de alerta inteligentes que detectan los problemas reales sin generar falsas alarmas debido a variaciones normales.
Considere las relaciones entre las métricas al investigar problemas. Un pico en la E/S del disco podría correlacionarse con una disminución en la tasa de aciertos de la caché del búfer y un aumento en los tiempos de ejecución de consultas. Comprender estas conexiones le ayuda a identificar las causas en lugar de solo los síntomas. Las revisiones periódicas de la planificación de la capacidad utilizando tendencias históricas garantizan que pueda escalar de forma proactiva antes de alcanzar las limitaciones de recursos.
Pasar de una simple monitorización del tiempo de actividad a una monitorización integral del rendimiento tendrá un impacto significativo en la forma en que comprende y gestiona sus bases de datos. Al centrarse en las métricas que afectan directamente al rendimiento de las aplicaciones y la experiencia del usuario, puede pasar de la extinción reactiva de incendios a la optimización proactiva, garantizando así un rendimiento consistente y fiable para sus bases de datos.




